
model distillation
current implementations and new ideas

Knowledge distillation is probably one of the most interesting rabbit holes I’ve gone down recently. I previously thought it was used to simply convert very large LLMs to smaller LLMs while maintaining accuracy, but there are a lot of unique takes and cool applications.
What is knowledge distillation?
I alluded to it above but the idea is that we can take large scaled models and make them smaller while maintaining accuracy. It works by transferring knowledge from something we call a teacher model to smaller student models. Enjoy my cute little graphic that attempts to show the transfer of knowledge lol. The teacher model, shown in pink, is a model that is much larger and likely has been exposed to more data, and therefore, in theory, will produce a more accurate result. The teacher is trying to convert its knowledge to these smaller student models.
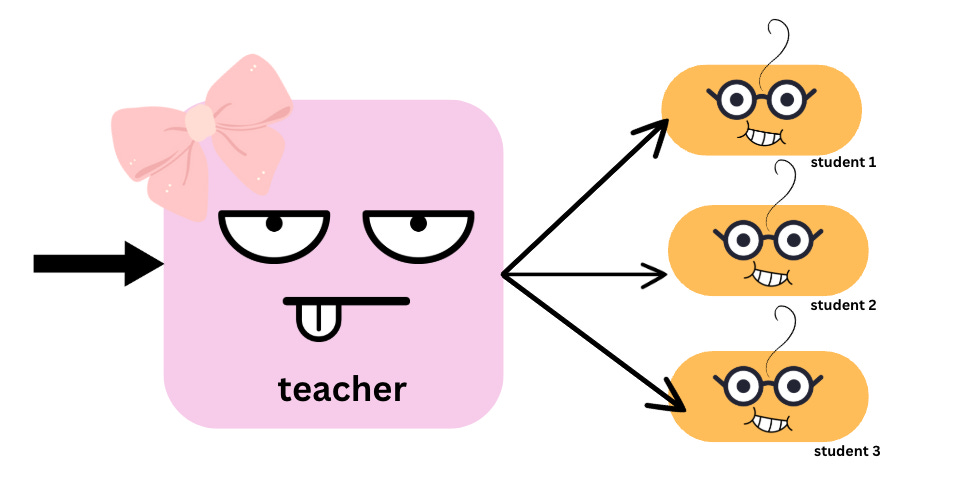
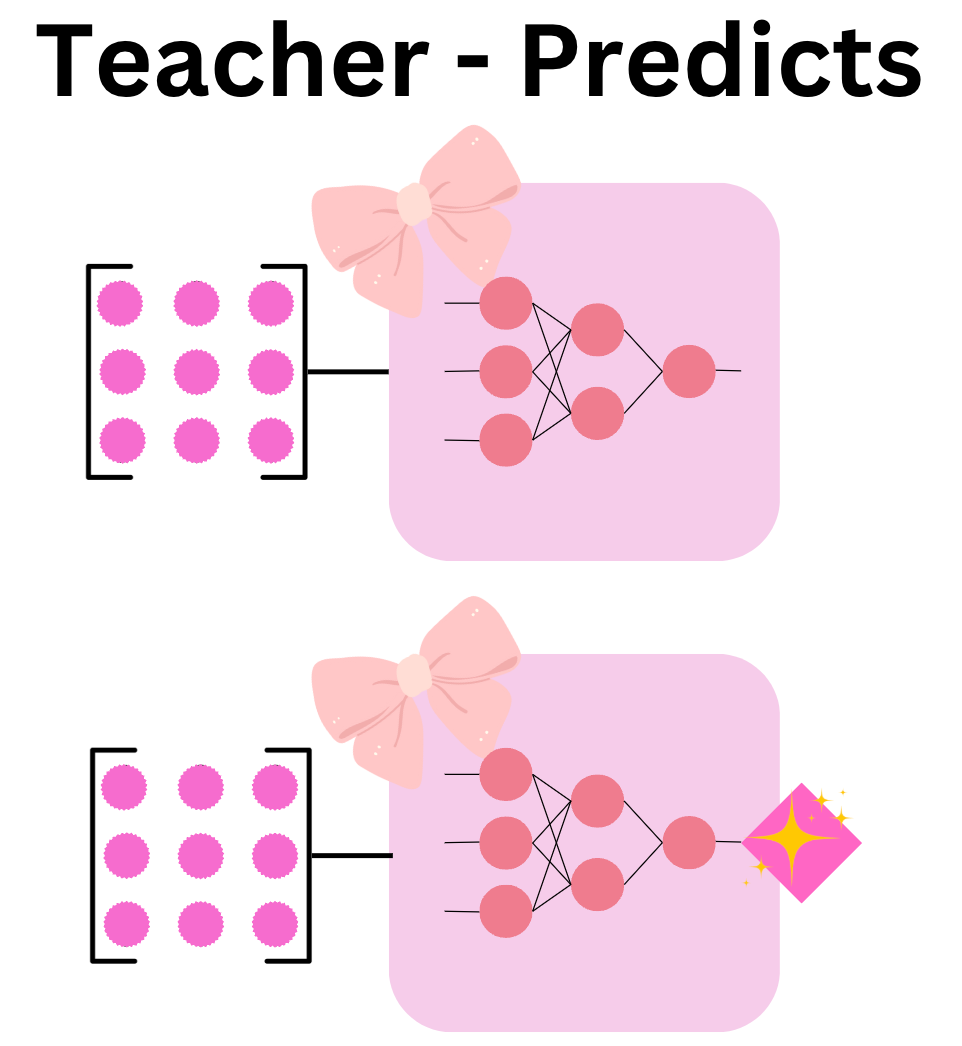
You’re probably wondering what transferring knowledge, means/looks like. Depending on the type of model this process will potentially look different, but the higher-level idea is some value is fed into the teacher model, and the teacher makes some predictions based on the inputs. That prediction then becomes a hard label for student models.
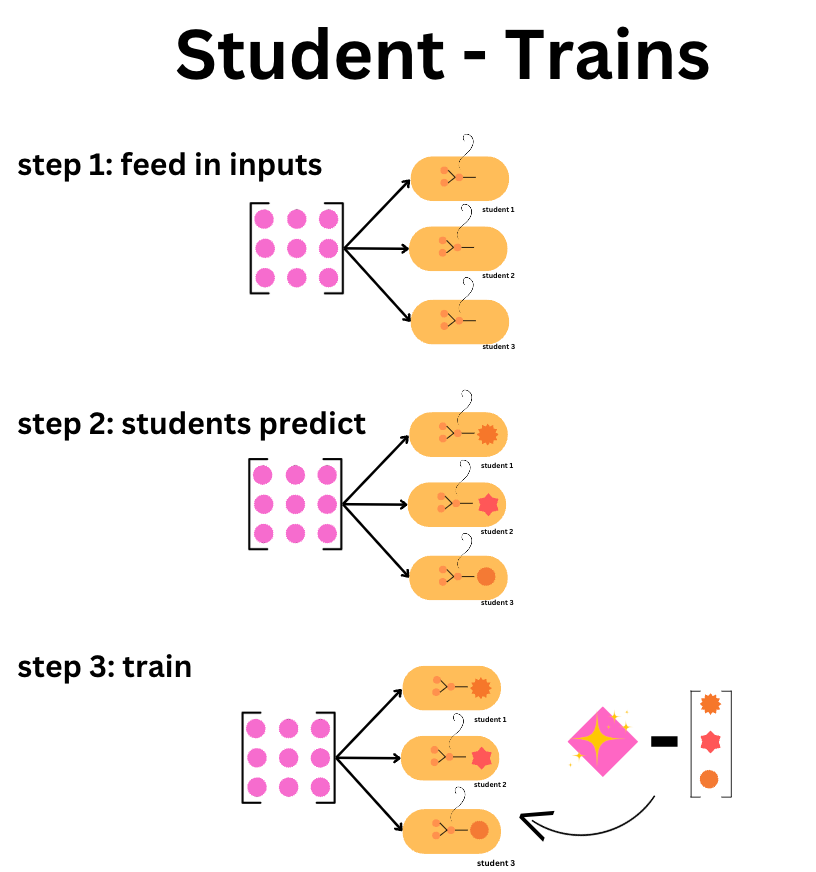
The students are then fed the same value as the teacher and their predictions are “scored” against the prediction the teacher model made. So each of the student models are fed in the same inputs that the teacher model was fed, they then make some predictions and their loss is calculated relative to the result the teacher made previously.
This method has proven to be very useful when trying to capture the knowledge from much larger, more capable models. There are also many research efforts playing around with the construction of the teacher model. Methods range from incredibly larger LLMs to model ensembles.
Cool research use cases:
Deepseek’s use of one of OpenAI’s older models
YouTube’s recommendation algorithm
Essentially anything you can think of that would originally require a complex model to perform the task, running on smaller devices. In autonomous vehicles and smart transportation, distilled models power real time perception, object detection, and navigation on low-power edge devices, enabling self-driving cars, smart traffic lights, and shared mobility services like e-scooters to operate efficiently even when out of network range. In IoT and embedded AI, smart home assistants, industrial sensors, and wearable health monitors leverage lightweight models for tasks like speech recognition, predictive maintenance, and real-time health tracking without constant cloud reliance. Similarly, mobile applications benefit from on-device AI for features such as image recognition, personalized recommendations, and augmented reality, enhancing user experiences while improving speed and privacy. By enabling complex AI tasks to run on smaller, low-power hardware, knowledge distillation is driving advancements in edge computing, IoT, and mobile AI, making intelligent systems more scalable and efficient.
I see there being a lot of new potential untapped applications of this technology, specifically in outdated spaces that aren’t levergaing AI because of hardware constraints. Here are a few ideas I think might be super interesting to explore:
Drug discovery and protein structure prediction
Currently models such as DeepMind’s AlphaFold require massive computational resources, but lightweight distilled models could democratize these capabilities, bringing advanced molecular analysis to smaller research labs and even point of care diagnostics in remote areas.
Precision Agriculture
Everywhere I’ve seen it done, AI powered crop monitoring and disease detection are heavily cloud-dependent, distilled models could potentially enable real time, on device analysis
Excellent read Brooke.